
corp.ling.stats is a research blog by Sean Wallis focusing on the intersection between corpus linguistics research and mathematical statistics and probability theory. About this blog • Latest…
News
Out now… Statistics in Corpus Linguistics Research (Routledge)
I am very pleased to announce that my new book, Statistics in Corpus Linguistics Research, is now available from Routledge. Drawing on more than ten years of research, and containing a large quantity of material never published before, the book is written for corpus linguistics researchers of all kinds, from students of corpus linguistics wishing to apply statistical analysis for the first time,…
Confidence intervals
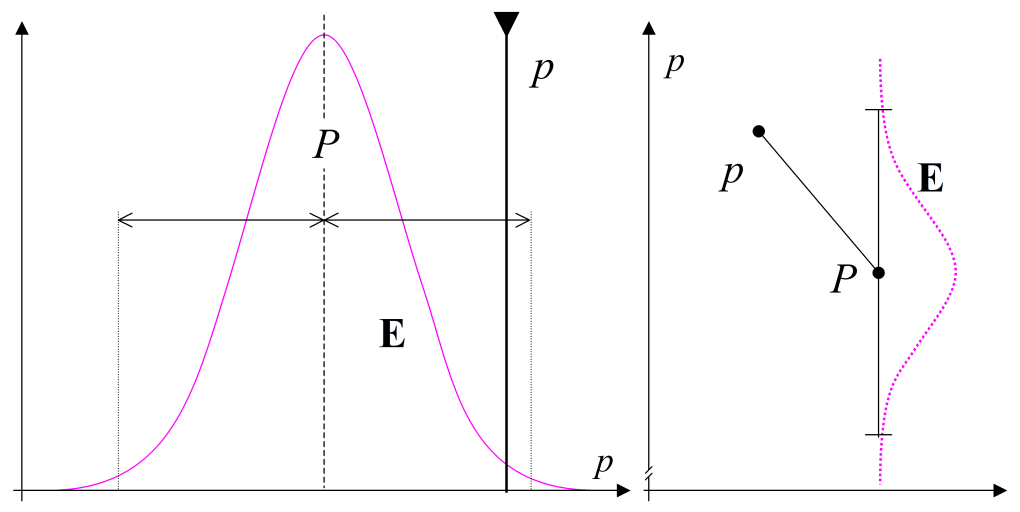
Confidence intervals
In this blog we identify efficient methods for computing confidence intervals for many properties. When we observe any measure from sampled data, we do so in order to estimate the most likely value in the population of data – ‘the real world’, as it were – from which our data was sampled. This is subject to a small number of assumptions (the sample is randomly drawn without bias, for example). But this observed value is merely the best estimate we have, on the information available.…
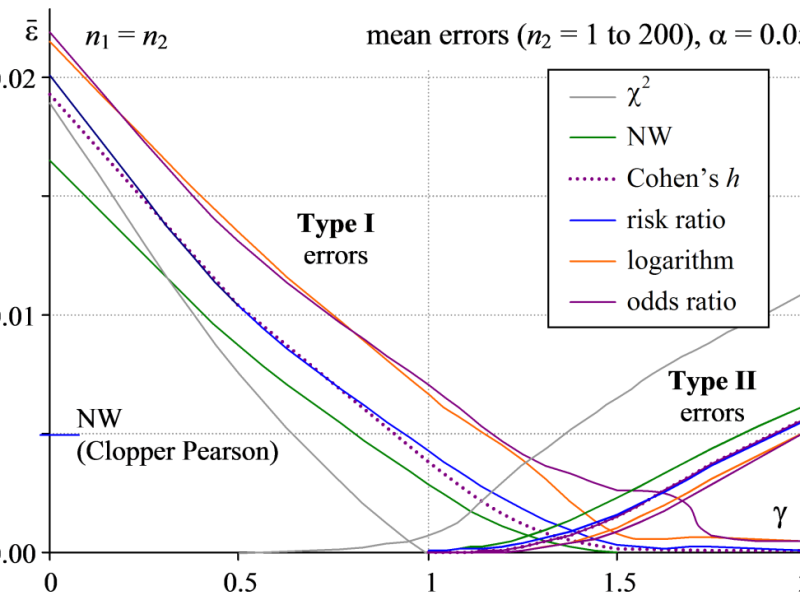
Continuity correction for risk ratio and other intervals
Introduction In An algebra of intervals we showed that we can calculate confidence intervals for formulae composed of common mathematical operators, including powers and logarithms. We employed a method proposed by Zou and Donner (2008), itself an extension of Newcombe (1998). Wallis (forthcoming) describes the method more formally. However, Newcombe’s method is arguably better-founded mathematically…
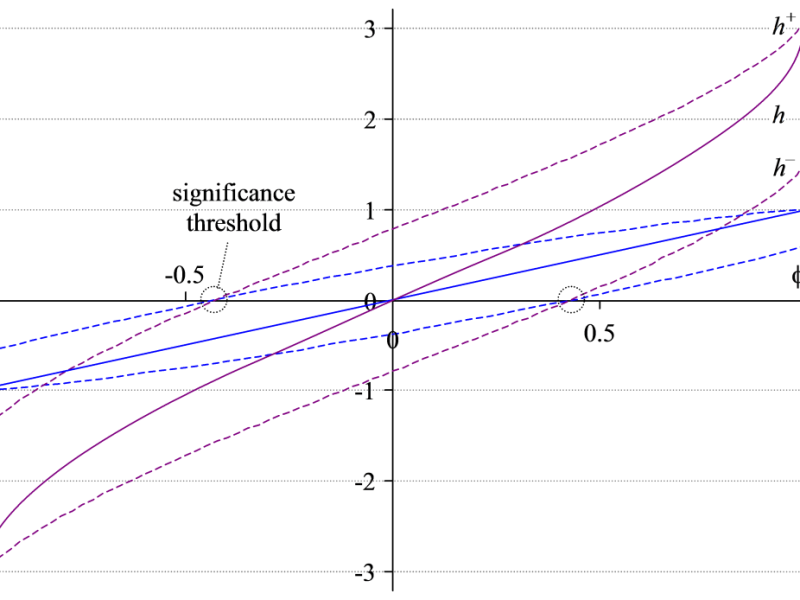
Confidence intervals for Cohen’s h
1. Introduction Cohen’s h (Cohen, 2013) is an effect size for the difference of two independent proportions that is sometimes cited in the literature. h ranges between minus and plus pi, i.e. h ∈ [–π, π]. Jacob Cohen suggests that if |h| > 0.2, this is a ‘small effect size’, if |h| > 0.5, it…
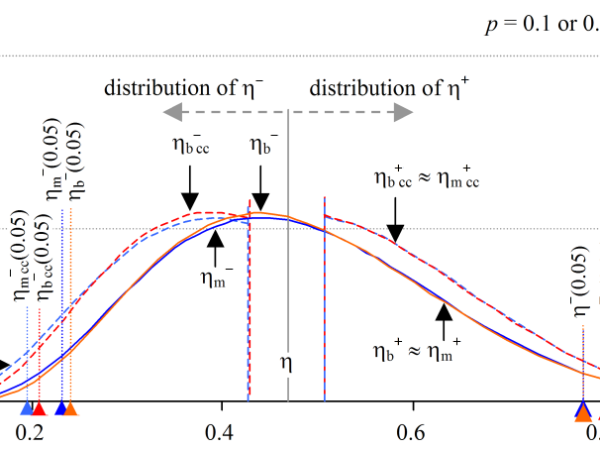
Plotting entropy confidence interval distributions
Introduction In this blog post, I will discuss the distribution of confidence intervals for the information-theoretic measure, entropy. One of the problems we face when reasoning with statistical uncertainty concerns our ability to mentally picture its shape. As students we were shown the Normal distribution and led to believe that it is reasonable to assume…
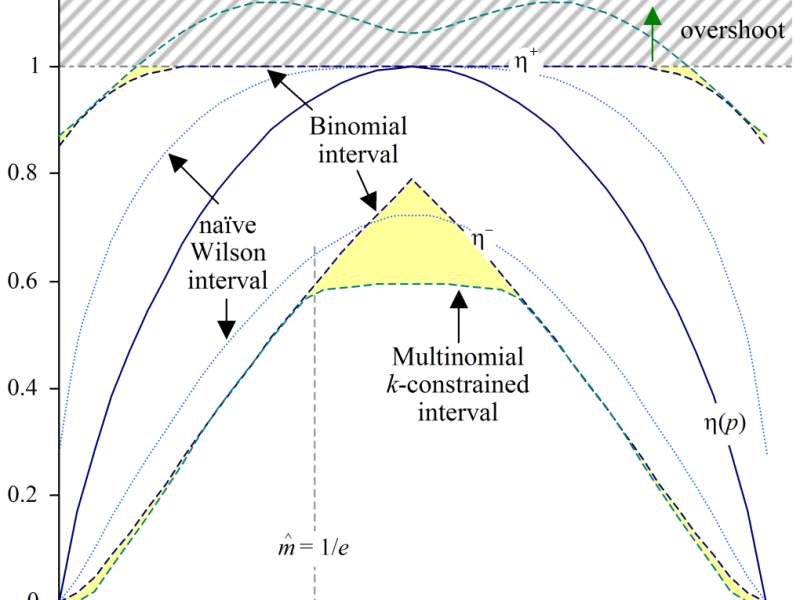
The confidence of entropy – and information
Introduction Two measures that are sometimes found in linguistic studies are information, defined as the negative log of the probability, and entropy. These are information-theoretic measures first defined by Claude Shannon (see e.g. Shannon and Weaver 1949). Entropy is also found in mutual information scores. This blog post is not intended to introduce information theory,…
Loading…
Something went wrong. Please refresh the page and/or try again.
Designing experiments
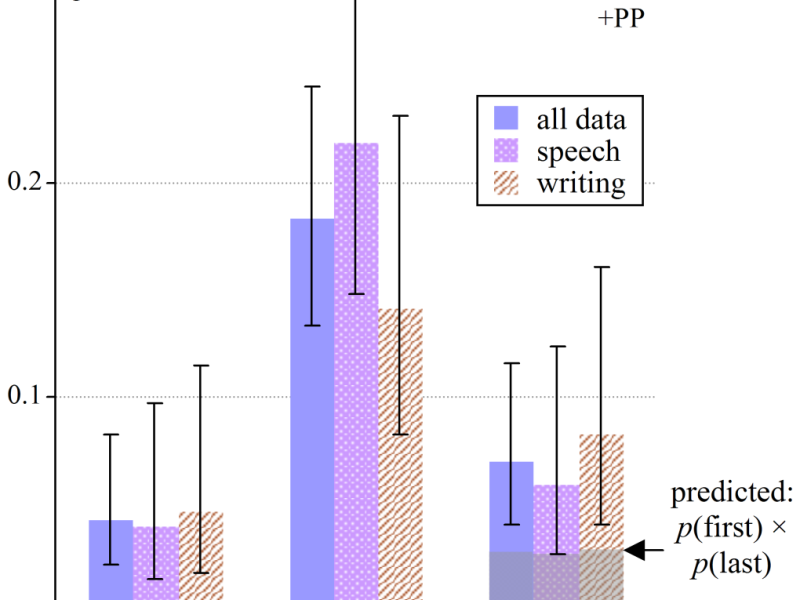
Directional evidence revisited
End weight bias and templating in conjoined phrase postmodification Abstract Full Paper (PDF) The tendency of speakers and writers to place larger constructions at the end of sentences, whether consciously or unconsciously, is well established. Often this question of ‘end weight’ is usually discussed in relation to grammatical transformations. In this short paper we demonstrate…
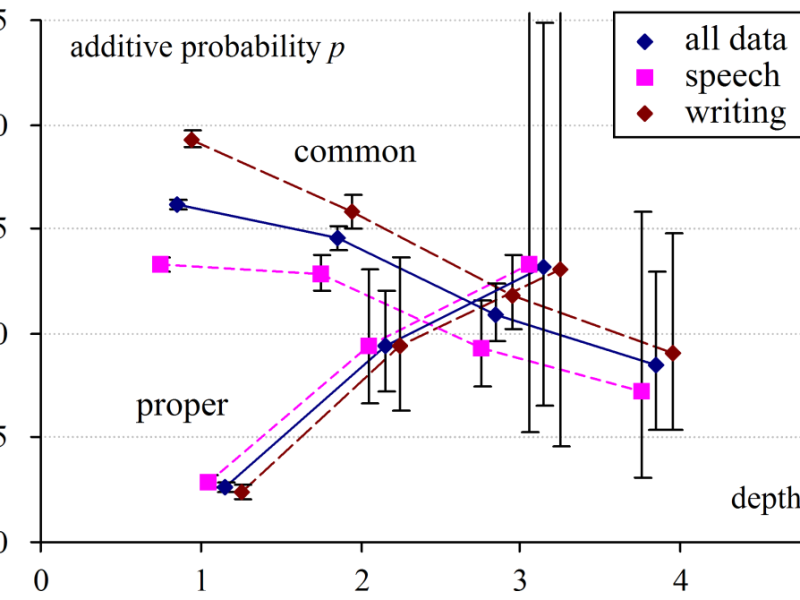
Are embedding decisions independent?
Evidence from preposition(al) phrases Abstract Full Paper (PDF) One of the more difficult challenges in linguistics research concerns detecting how constraints might apply to the process of constructing phrases and clauses in natural language production. In previous work (Wallis 2019) we considered a number of operations modifying noun phrases, including sequential and embedded modification with…
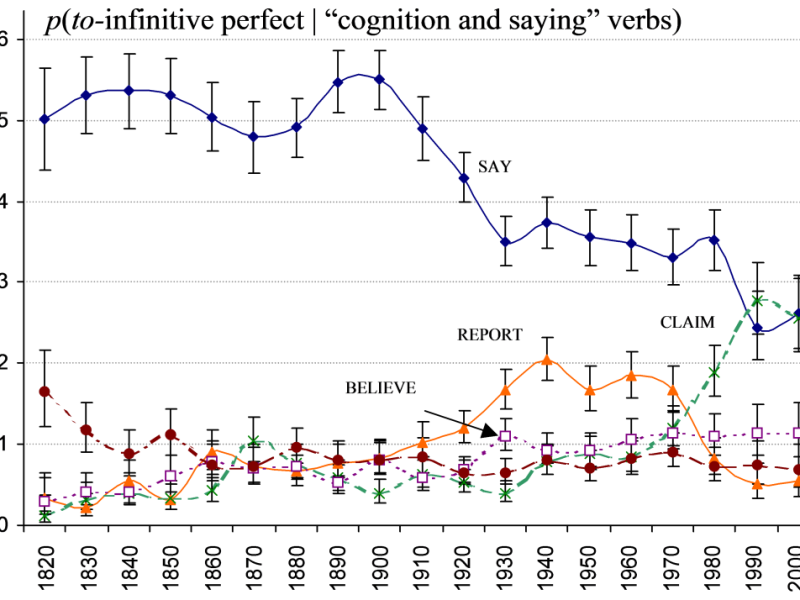
The replication crisis: what does it mean for corpus linguistics?
Introduction Over the last year, the field of psychology has been rocked by a major public dispute about statistics. This concerns the failure of claims in papers, published in top psychological journals, to replicate. Replication is a big deal: if you publish a correlation between variable X and variable Y — that there is an…
What might a corpus of parsed spoken data tell us about language?
Abstract Paper (PDF) This paper summarises a methodological perspective towards corpus linguistics that is both unifying and critical. It emphasises that the processes involved in annotating corpora and carrying out research with corpora are fundamentally cyclic, i.e. involving both bottom-up and top-down processes. Knowledge is necessarily partial and refutable. This perspective unifies ‘corpus-driven’ and ‘theory-driven’…
Loading…
Something went wrong. Please refresh the page and/or try again.
Contingency tests and latest posts…
